インテルのみ表示可能 — GUID: rxr1533827311846
Ixiasoft
1.1. コンパイルの概要
1.2. Compilation Dashboardの使用
1.3. デザイン・ネットリストのインフラストラクチャー (ベータ版)
1.4. デザインの合成
1.5. デザインの配置配線
1.6. インクリメンタル最適化フロー
1.7. Fast Forwardコンパイルフロー
1.8. フルコンパイル・フロー
1.9. コンパイル結果のエクスポート
1.10. 他のEDAツールの統合
1.11. 合成言語のサポート
1.12. コンパイラーの最適化手法
1.13. 合成設定のリファレンス
1.14. フィッター設定のリファレンス
1.15. デザインのコンパイルの改訂履歴
インテルのみ表示可能 — GUID: rxr1533827311846
Ixiasoft
1.12.6. フラクタル合成の最適化
フラクタル合成の最適化は、ディープラーニング・アクセラレーターや、その他の高スループット、算術演算多用デザインが、利用可能なすべてのDSPリソースを上回る場合に役立ちます。このようなデザインの場合、フラクタル合成の最適化により、20%から45%の領域を削減することができます。
フラクタル合成は一連の合成最適化で、算術演算を多用するデザインにFPGAリソースを最適な方法で使用します。この合成の最適化は、乗算器の正則化とリタイミング、および連続算術パッキングで構成されます。この最適化は、低精度の算術演算 (加算や乗算など) を多数使用するデザインをターゲットにしています。フラクタル合成は、グローバルに、または特定の乗算器に対して有効にすることができます。詳細は、フラクタル合成の有効化または無効化 で説明しています。
プロジェクト全体のフラクタル合成に関する考慮事項
注: フラクタル合成の最適化は、ディープラーニング・アクセラレーターを備えるデザインや、他の高スループットで算術演算を多用する機能がすべてのDSPリソースを上回るデザインに最も有効です。フラクタル合成をプロジェクト全体で有効にすると、フラクタル最適化に適していないモジュールで不要な肥大化が発生することがあります。フラクタル合成の最適化をプロジェクト全体で有効にする前に、次の内容を考慮します。
- インテルFPGAデバイスには、算術演算に非常に適した数千のハードDSPブロックがあります。デザインの算術演算機能の総数が少ない場合は、フラクタル合成を有効にする必要はありません。このような場合、すべての算術演算機能はデフォルトでDSPに直接マッピングされます。グローバルフラクタル合成は、利用可能なDSPブロックですべての算術演算コンポーネントを実装できない場合にのみ有効にします。フラクタル合成は、コンパイラーでのDSPへのマッピングを望まないモジュールでのみ有効にします。
- 現在のバージョンの インテル® Quartus® Primeプロ・エディション・ソフトウェアでは、フラクタル合成の最適化は、低精度の乗算をターゲットにしています。高精度の乗算器 (各オペランドの幅が11ビットを超える) の実装には、DSPブロックを使用します。
- フラクタル合成をプロジェクト全体で有効にすると、次に示す情報メッセージ番号20193がコンパイル時に生成されることがあります
Applied dense packing to "<entity>". Area: 2 LABs. Logic density: 0.775.
この情報は、コンパイラーによる作業で計算ロジックを少数のLABにパッキングしていることを示すものです。デザインの使用率がすでに高い場合、コンパイラーではこのステージを省略することができます。
- メッセージで示されるAreaが100 LABを超えていないことを確認します。100 LABを超えている場合は、フラクタル合成ブロックをサブブロックに分割し、フラクタル合成最適化をサブブロックに個別に割り当てます。
- メッセージで示されるLogic densityが0.75より大きいことを確認します。0.75未満の場合は、このエンティティーの Fractal Synthesis を無効にします。この場合は、標準の合成を行うことで、より良い密度を達成することができます。
| 領域 (LAB) | |||
|---|---|---|---|
| デバイス | ドット積 | フラクタル合成がONの場合 | フラクタル合成がOFFの場合 |
| インテル® Arria® 10および インテル® Cyclone® 10 GX | 16 4x4smの合計 | 12 | 19 |
| 16 5x5smの合計 | 19 | 32 | |
| 16 6x6smの合計 | 25 | 36 | |
| 16 7x7smの合計 | 34 | 44 | |
| 16 8x8smの合計 | 45 | 60 | |
| インテル® Stratix® 10およびIntel Agilex® 7デバイス | 16 4x4smの合計 | 15 | 22 |
| 16 5x5smの合計 | 21 | 39 | |
| 16 6x6smの合計 | 29 | 47 | |
| 16 7x7smの合計 | 39 | 55 | |
| 16 8x8smの合計 | 55 | 71 | |
乗算器の正則化とリタイミング
乗算器の正則化とリタイミングでは、高度に最適化されたソフト乗算器の実装を推論します。コンパイラーは必要に応じて、後方リタイミングを2つ以上のパイプライン・ステージに適用します。フラクタル合成を有効にすると、コンパイラーは、乗算器の正則化とリタイミングを符号付きおよび符号なし乗算器に適用します。
図 106. 乗算器のリタイミング
注:
- 乗算器の正則化では、ロジックリソースのみを使用します。DSPブロックは使用しません。
- 乗算器の正則化とリタイミングは、FRACTAL_SYNTHESIS QSF 割り当てが設定されているモジュールの符号付き乗算器と符号なし乗算器の両方に適用されます。
乗算器正則化例
次のシンプルな符号なしドット積のデザイン例には、5ビット・オペランドの乗算演算子が含まれています。このような短い乗算器は、乗算器の正則化に最適な候補です。
(* altera_attribute = "-name FRACTAL_SYNTHESIS ON" *)
module dot_product(
input clk,
input [4:0] a, b, c, d, e, f, g, h,
output reg [11:0] out
);
reg [9:0] ab, cd, ef, gh;
reg [10:0] ab_cd, ef_gh;
always @(posedge clk)
begin
ab <= a * b;
cd <= c * d;
ef <= e * f;
gh <= g * h;
ab_cd <= ab + cd;
ef_gh <= ef + gh;
out <= ab_cd + ef_gh;
end
endmodule
module top(
input clk,
input [4:0] a1, b1, c1, d1, e1, f1, g1, h1,
input [4:0] a2, b2, c2, d2, e2, f2, g2, h2,
output [11:0] out1, out2
);
dot_product core1(.clk(clk), .a(a1), .b(b1), .c(c1), .d(d1),
.e(e1), .f(f1), .g(g1), .h(h1), .out(out1));
dot_product core2(.clk(clk), .a(a2), .b(b2), .c(c2), .d(d2),
.e(e2), .f(f2), .g(g2), .h(h2), .out(out2));
endmodule
インテル® Quartus® Primeの合成では、次のメッセージをコンソールに出力します。
図 107. コンソールのメッセージ
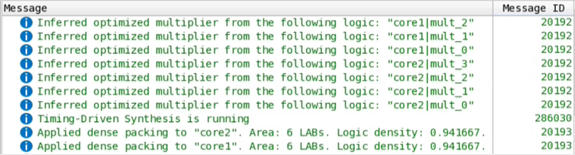
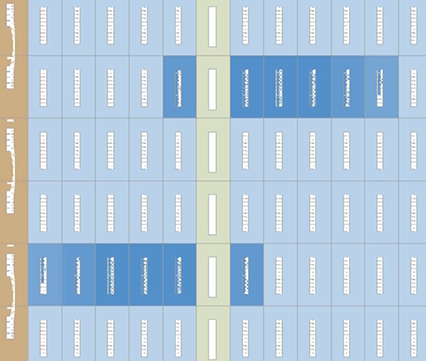
Chip Plannerには、このデザインに符号なしドット積のコアが2つあることが示されます。この2つのコアは、個別に最適化され、配置されています。LABリソースは、次の図に示すように、ほぼ100%最適化されています。
図 108. デザインの配置
符号付きドット積は、ディープラーニング・アプリケーションで広く使われています。次に、符号付きドット積の例を示します。
(* altera_attribute = "-name FRACTAL_SYNTHESIS ON" *)
module dot_product(
input signed clk,
input signed [4:0] a, b, c, d, e, f, g, h,
output reg signed [11:0] out
);
reg signed [9:0] ab, cd, ef, gh;
reg signed [10:0] ab_cd, ef_gh;
always @(posedge clk)
begin
ab <= a * b;
cd <= c * d;
ef <= e * f;
gh <= g * h;
ab_cd <= ab + cd;
ef_gh <= ef + gh;
out <= ab_cd + ef_gh;
end
endmodule
module top(
input clk,
input signed [4:0] a1, b1, c1, d1, e1, f1, g1, h1,
input signed [4:0] a2, b2, c2, d2, e2, f2, g2, h2,
output signed [11:0] out1, out2
);
dot_product core1(.clk(clk), .a(a1), .b(b1), .c(c1), .d(d1),
.e(e1), .f(f1), .g(g1), .h(h1), .out(out1));
dot_product core2(.clk(clk), .a(a2), .b(b2), .c(c2), .d(d2),
.e(e2), .f(f2), .g(g2), .h(h2), .out(out2));
endmodule
インテル® Quartus® Primeの合成では、次のメッセージをコンソールに出力します。
図 109. コンソールのメッセージ
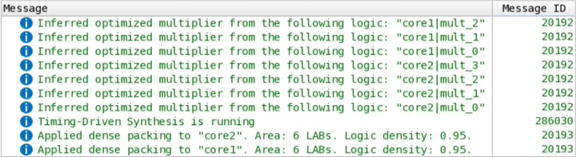
Chip Plannerには、このデザインに符号付きドット積のコアが2つあり、個別に最適化されて配置されていることが示されます。
図 110. デザインの配置

連続算術パッキング
連続算術パッキングでは、算術ゲートを最適なサイズのロジックブロックに再合成し、 インテル® FPGA LABにフィットさせます。この最適化により、算術ブロックに対してLABリソース使用率を最大100%にすることができます。
フラクタル合成を有効にすると、コンパイラーは、この最適化をすべてのキャリーチェーンと2入力のロジックゲートに適用します。この最適化では、加算器ツリー、乗算器、およびその他の算術演算関連ロジックをパッキングすることができます。
図 111. 連続算術パッキング
連続算術パッキングは、乗算器の正則化とは無関係に動作することに注意してください。したがって、正則化されていない乗算器を使用している場合 (独自の乗算器を作成している場合など) でも、連続算術パッキングは動作します。