インテルのみ表示可能 — GUID: efk1511996063310
Ixiasoft
3.1.1. ポインター・インターフェイス
CPUをターゲットとするコードの作成に慣れているソフトウェア開発者は、まず、このアルゴリズムのコーディングを試すために、ベクトル a 、 b 、および c をポインターとして宣言して、コンポーネントへのデータを出し入れを行うかもしれません。
ポインターをこのように使用すると、単一のAvalon Memory-Mapped (MM) Masterインターフェイスが作成され、それを3つの入力変数で共有します。
コンポーネント内のポインターは、 Avalon® Memory Mapped (Avalon-MM) として、デフォルト設定で実装されます。ポインター・パラメーター・インターフェイスについて詳しくは、 Intel High Level Synthesis Compiler Pro Edition Reference Manual内の Intel HLS Compiler Default Interfacesを参照してください。
ポインター・インターフェイスを使用したベクトル加算のコンポーネント例のコーディングは、次のように行います。
component void vector_add(int* a,
int* b,
int* c,
int N) {
#pragma unroll 8
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
}
次の図で示すComponent Viewerレポートは、この例をコンパイルする際に生成されるものです。ループの展開は、係数8によって行われるため、図で示しているとおり、vector_add.B2 には、ベクトル a に対しては8ロード、ベクトル b に対しては8ロード、ベクトル c に対しては8ストアあります。さらに、ロードとストアはすべて、同じメモリー上でアービトレーションされ、メモリーアクセスが非効率的になります。
図 1. ポインター・インターフェイスでの vector_add コンポーネントのGraph Viewer Function View

次のLoop Analysisレポートで示しているとおり、コンポーネントのループ開始間隔 (II) が大きくなってしまっています。IIが大きいのは、ベクトル a 、 b 、および c からのアクセスがすべて、同じAvalon-MM Masterインターフェイスを介して行われるためです。 インテル®HLSコンパイラー プロ・エディションでは、ストール可能なアービトレーション・ロジックを使用してこのようなアクセスをスケジュールします。これにより、パフォーマンスが低下し、FPGA領域の使用率が高くなります。
さらに、コンパイラーでは、ループ・イタレーション間にデータ依存関係がないと仮定することはできません。これは、ポインターのエイリアシングが存在する可能性があるためです。コンパイラーでは、ベクトル a 、 b 、および c が重複していないことは、判定できません。データの依存関係が存在する場合、 インテル®HLSコンパイラーでは、ループ・イタレーションの効果的なパイプライン処理はできません。
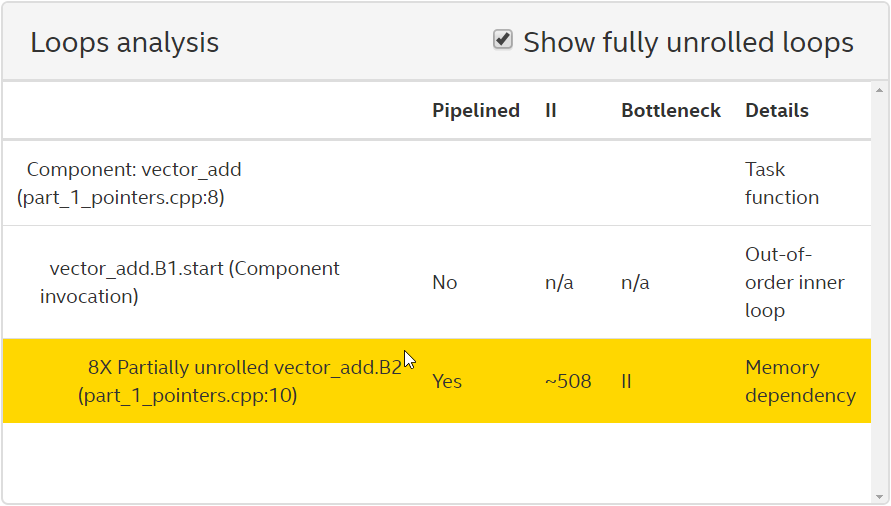
コンポーネントのコンパイルは、 インテル® Quartus® Primeのコンパイルフローを使用し、 インテル® Arria® 10デバイスをターゲットとする場合、その結果は次のQoRメトリックになります。これには、ALMの高使用量、高レイテンシー、高II、低fmax などがあります。これはすべて、コンポーネント内では望ましくないプロパティーです。
| QoRメトリック | 値 |
|---|---|
| ALM | 15593.5 |
| DSP | 0 |
| RAM | 30 |
| fmax (MHz)2 | 298.6 |
| レイテンシー (サイクル) | 24071 |
| 開始間隔 (II) (サイクル) | 約508 |
| 1QoRメトリックの計算に使用されたコンパイルフローでは、インテル Quartus Prime プロ・エディションのバージョン17.1を使用しています。 |
| 2fmax の測定値は1シードから計算しています。 |