インテルのみ表示可能 — GUID: kxo1511996056004
Ixiasoft
3.1.3. Avalon® Memory Mappedスレーブ・インターフェイス
コンポーネントによっては、コンポーネントのメモリー構造の最適化できることがあります。このためには、 Avalon® Memory Mapped Avalon® (Avalon MM) スレーブ・インターフェイスを使用します。
スレーブメモリーの割り当ての際には、そのサイズを定義してください。サイズを定義すると、コンポーネントによって処理可能な N の値に制限が課されます。この例では、RAMサイズは1024ワードです。このRAMサイズの意味は、N が持つことができる最大サイズは1024ワードであるということです。
ベクトル加算コンポーネント例のコーティングは、 Avalon® MMスレーブ・インターフェイスを使用して次のように行います。
component void vector_add(
hls_avalon_slave_memory_argument(1024*sizeof(int)) int* a,
hls_avalon_slave_memory_argument(1024*sizeof(int)) int* b,
hls_avalon_slave_memory_argument(1024*sizeof(int)) int* c,
int N) {
#pragma unroll 8
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
}
次の図で示すGraph ViewerのFunction Viewは、この例をコンパイルしたときに生成されるものです。
図 3. Avalon® MMスレーブ・インターフェイスでの vector_addコンポーネントのGraph Viewer Function View
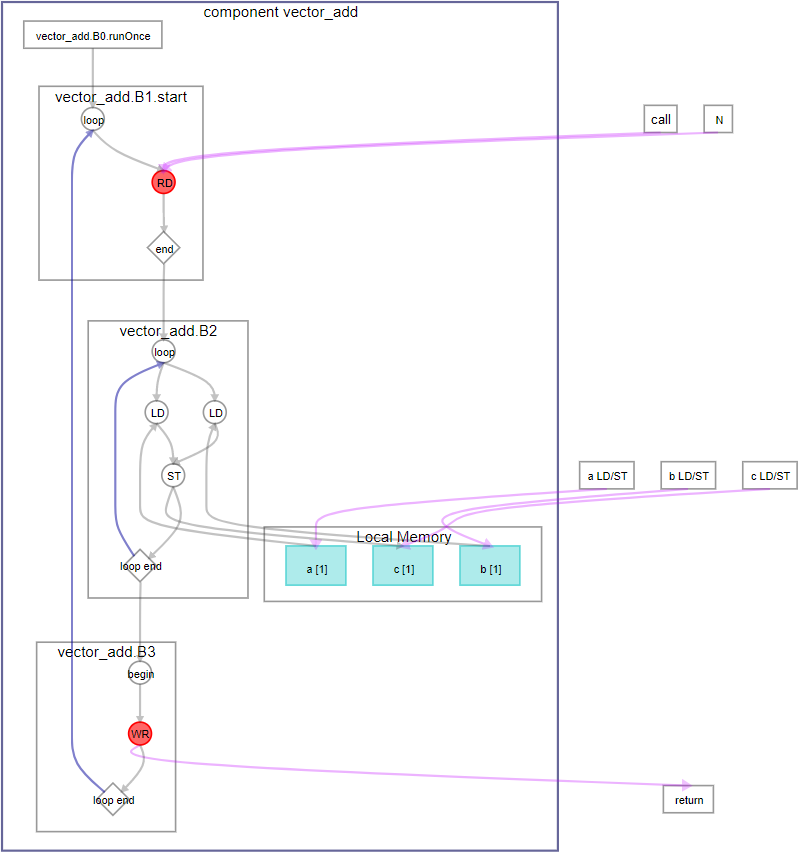
このコンポーネントのコンパイルは、 インテル® Quartus® Primeのコンパイルフローを使用して インテル® Arria® 10デバイスをターゲットとした場合、その結果は次のQoRメトリックになります。
QoRメトリックで示しているとおり、メモリーの所有権をシステムからコンポーネントへ変更することで、コンポーネントで使用するALM数が減少します。コンポーネント・レイテンシーも同様に減少します。コンポーネントのfMAX は増加します。コンポーネントで使用するRAMブロックの数は増加します。これは、メモリーが実装先はシステムではなくコンポーネントだからです。システムRAMの合計使用率 (表中に記載なし) は増加しないはずです。これは、RAM使用率が、システムからFPGA RAMブロックへシフトされるためです。
| QoR メトリック | ポインター | Avalon® MMマスター | Avalon® MMスレーブ |
|---|---|---|---|
| ALM | 15593.5 | 643 | 490.5 |
| DSP | 0 | 0 | 0 |
| RAM | 30 | 0 | 48 |
| fMAX (MHz)2 | 298.6 | 472.37 | 498.26 |
| レイテンシー (サイクル) | 24071 | 142 | 139 |
| 開始間隔 (II) (サイクル) | ~508 | 1 | 1 |
| 1QoRメトリックの計算に使用されたコンパイルフローでは、インテル Quartus Prime プロ・エディションのバージョン17.1を使用しています。 |
| 2fmax の測定値は1シードから計算しています。 |