5.4. 例 : ローカル・メモリー・アドレスのバンク選択ビットの指定
オプションで、ローカルメモリー・アドレスのどのビットでメモリーバンクを選択し、どのビットでそのバンクのワードを選択するのかを インテル®HLSコンパイラー プロ・エディションに知らせることができます。バンク選択ビットの指定には、hls_bankbits(b 0, b 1, ..., b n) 属性を使用します。
(b 0 , b 1 , ... ,b n ) 引数では、ローカル・メモリー・アドレスのビット位置を参照します。 インテル®HLSコンパイラー プロ・エディションでは、このビット位置をバンク選択ビットに使用します。hls_bankbits(b 0, b 1 , ..., b n) 属性の指定は、バンクの数が 2 number of bank bits に等しいことを意味します。
| Bank 0 | Bank 1 | Bank 2 | Bank 3 | |
| Word 0 | 00 000 | 01 000 | 10 000 | 11 000 |
| Word 1 | 00 001 | 01 001 | 10 001 | 11 001 |
| Word 2 | 00 010 | 01 010 | 10 010 | 11 010 |
| Word 3 | 00 011 | 01 011 | 10 011 | 11 011 |
| Word 4 | 00 100 | 01 100 | 10 100 | 11 100 |
| Word 5 | 00 101 | 01 101 | 10 101 | 11 101 |
| Word 6 | 00 110 | 01 110 | 10 110 | 11 110 |
| Word 7 | 00 111 | 01 111 | 10 111 | 11 111 |
制約事項: 現在、hls_bankbits(b 0, b 1, ..., b n) 属性でサポートしているのは、連続するバンクビットのみです。
hls_bankbits 属性の実装例
次のコンポーネントコードの例を検討します。
1
component int bank_arbitration (int raddr,
int waddr,
int wdata) {
#define DIM_SIZE 4
// Adjust memory geometry by preventing coalescing
hls_numbanks(1)
hls_bankwidth(sizeof(int)*DIM_SIZE)
// Force each memory bank to have 2 ports for read/write
hls_singlepump
hls_max_replicates(1)
int a[DIM_SIZE][DIM_SIZE][DIM_SIZE];
// initialize array a…
int result = 0;
#pragma unroll
for (int dim1 = 0; dim1 < DIM_SIZE; dim1++)
#pragma unroll
for (int dim3 = 0; dim3 < DIM_SIZE; dim3++)
a[dim1][waddr&(DIM_SIZE-1)][dim3] = wdata;
#pragma unroll
for (int dim1 = 0; dim1 < DIM_SIZE; dim1++)
#pragma unroll
for (int dim3 = 0; dim3 < DIM_SIZE; dim3++)
result += a[dim1][raddr&(DIM_SIZE-1)][dim3];
return result;
}
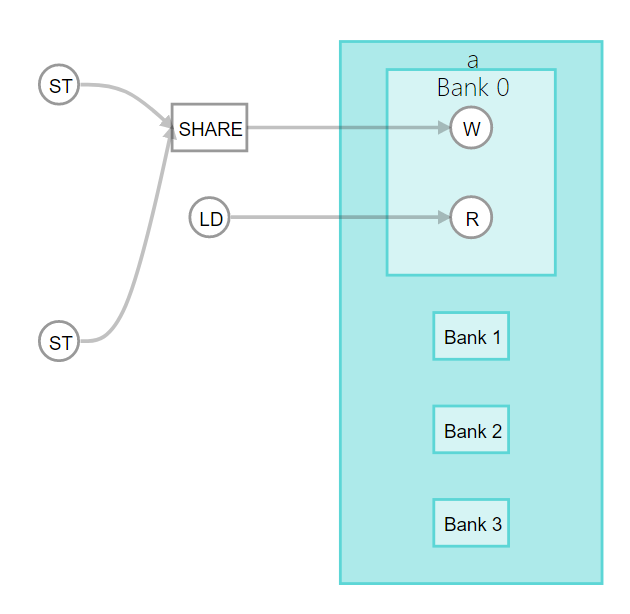
次の図で示すとおり、このコード例によって複数のロード/ストアユニット (LSU) が生成され、それによって、複数のロードおよびストア命令がハードウェアに生成されます。メモリーシステムが複数のバンクに分割されていない場合、メモリーアクセス命令よりもポート数が少なくなり、アービトレーションされたアクセスにつながります。このアービトレーションにより、ループ開始間隔 (II) の値が高くなります。アービトレーションは、可能な限り避けてください。これは、アービトレーションによってコンポーネントのFPGAエリアの使用率が増加し、コンポーネントのパフォーマンスが低下するためです。
図 18. コンポーネント bank_arbitration のローカルメモリーaへのアクセス

デフォルトでは、 インテル®HLSコンパイラー プロ・エディションでは、分割がコンポーネントのパフォーマンスに有益であると判断した場合、メモリーをバンクに分割します。コンパイラーでは、アクセス間で一定のビットが残っているかどうかを確認し、バンク選択ビットを自動的に推測します。
次のコンポーネントコードの例を検討します。
component int bank_no_arbitration (int raddr,
int waddr,
int wdata) {
#define DIM_SIZE 4
// Adjust memory geometry by preventing coalescing and splitting memory
hls_bankbits(4, 5)
hls_bankwidth(sizeof(int)*DIM_SIZE)
// Force each memory bank to have 2 ports for read/write
hls_singlepump
hls_max_replicates(1)
int a[DIM_SIZE][DIM_SIZE][DIM_SIZE];
// initialize array a…
int result = 0;
#pragma unroll
for (int dim1 = 0; dim1 < DIM_SIZE; dim1++)
#pragma unroll
for (int dim3 = 0; dim3 < DIM_SIZE; dim3++)
a[dim1][waddr&(DIM_SIZE-1)][dim3] = wdata;
#pragma unroll
for (int dim1 = 0; dim1 < DIM_SIZE; dim1++)
#pragma unroll
for (int dim3 = 0; dim3 < DIM_SIZE; dim3++)
result += a[dim1][raddr&(DIM_SIZE-1)][dim3];
return result;
}
次の図で示しているとおり、このサンプルコードによって作成されるメモリー・コンフィグレーションには4つのバンクが備わっています。ビット4および5をバンク選択ビットとして使用すると、各ロード/ストアアクセスは、確実にそれ自体のメモリーバンクに送られます。
図 19. コンポーネント bank_no_arbitration のローカルメモリーaへのアクセス
このコード例では、hls_bankbits(4,5) ではなく hls_numbanks(4) を設定すると、同じメモリー・コンフィグレーション結果になります。これは、 インテル®HLSコンパイラー プロ・エディションでは、最適なバンク選択ビットを自動的に推測するためです。
Function Memory Viewer (High-Level Design Report内) では、 Address bit information によって表示されるバンク選択ビットは、b6 および b7 です。b4 および b5 ではありません。

この違いが発生する理由は、Function Memory Viewerで報告されるアドレスビットが、要素アドレスではなくバイトアドレスに基づいているためです。配列 a のすべての要素のサイズは4バイトであるため、要素アドレスビットのビット b4 および b5 の対応先は、バイトアドレス指定のビット b6 および b7 になります。
1 この例では、初期コンポーネントの生成時の hls_numbanks 属性の設定は1 (hls_numbanks(1)) とされ、コンパイラーによってメモリーがバンクに自動分割されるのを防止しています。